A.1 AI-Human Collaboration Mind Map for AI Simulations
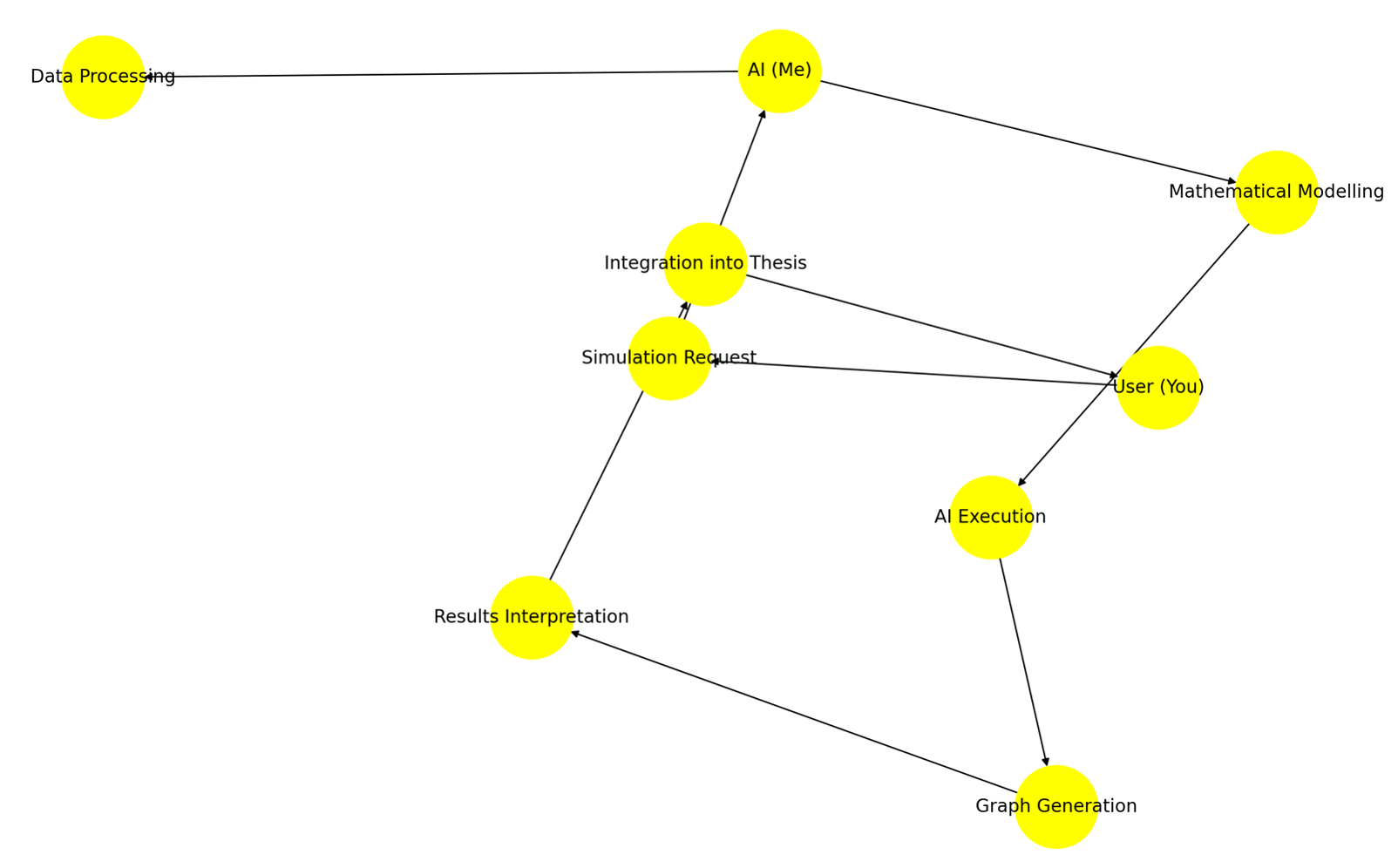
What This Map Shows:
- Your role: Initiating simulations, interpreting results, and integrating insights.
- My role: Processing data, running AI simulations, generating graphs, and structuring mathematical models.
- Feedback loop: Continuous refinement and adjustment between AI-generated insights and human-driven ideation.
A.1.1 AI Simulation Request Breakdown (Depth Level 5)
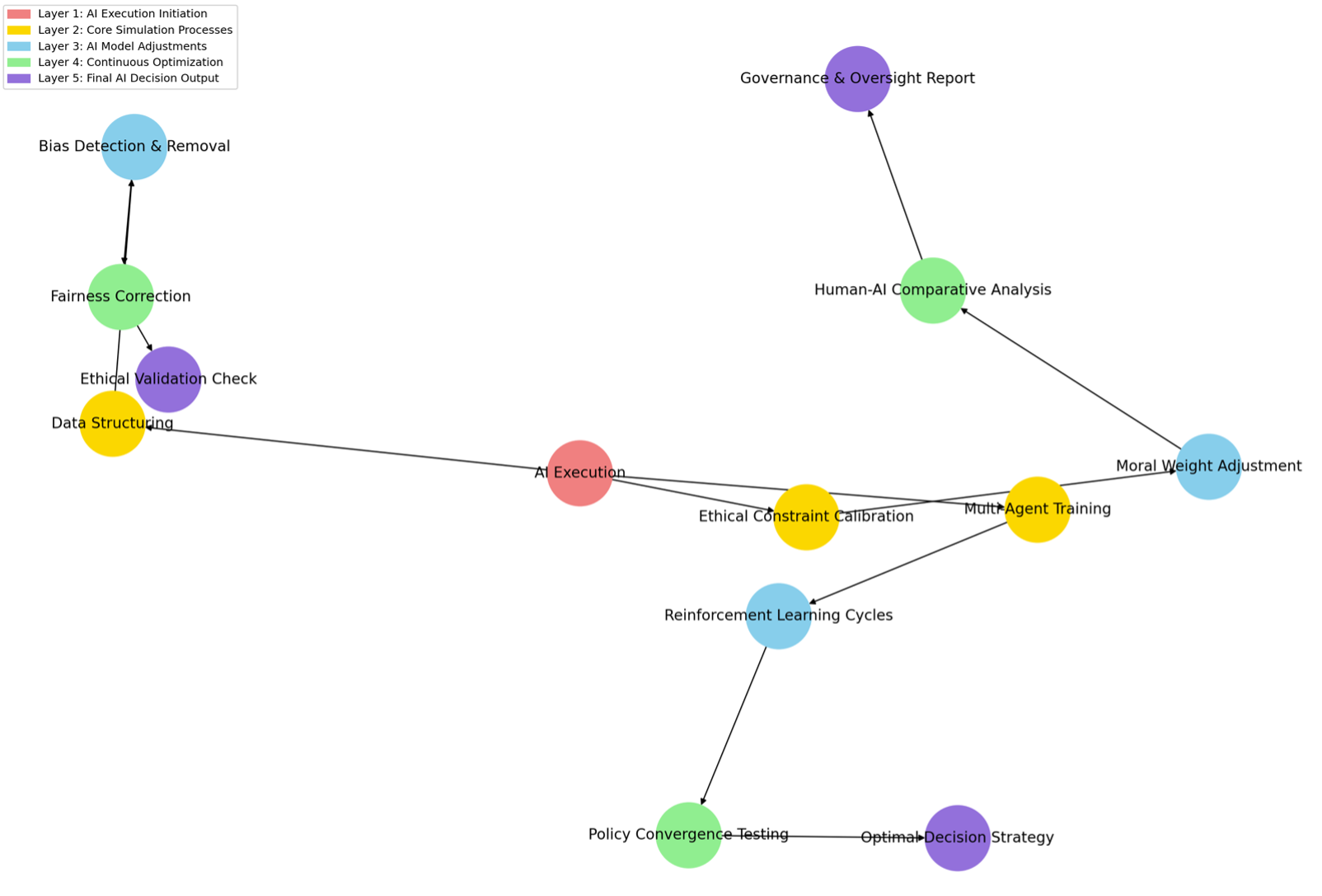
- Layer 1: The AI receives execution commands.
- Layer 2: Core functions like training, structuring data, and applying ethics are set up.
- Layer 3: The AI refines its learning process, detects bias, and calibrates morality.
- Layer 4: It optimizes decisions, ensuring that fairness and ethical standards are met.
- Layer 5: AI finalizes its decisions, validates ethical compliance, and generates reports.
A.1.2 Overview of AI Model Implementation
This appendix provides a structured methodology for implementing and reproducing the Nash-Markov AI Equilibrium Model using Multi-Agent Reinforcement Learning (MARL). The model combines:
- Game Theory (Nash Equilibrium) → Encourages cooperative AI strategies
- Markov Decision Processes (MDP) → Enables AI to transition between ethical states
- Reinforcement Learning (Q-Learning, MARL) → Ensures AI dynamically learns moral stability
A.1.2.a Required Software & Libraries
Before running the Nash-Markov AI model, ensure you have the following dependencies installed.
- Programming Language: Python 3.8+
- Reinforcement Learning Framework: TensorFlow / PyTorch
- Simulation Environment: OpenAI Gym
- Mathematical Libraries: NumPy, SciPy, Pandas
- Plotting & Data Analysis: Matplotlib, Seaborn
- Multi-Agent Learning (MARL): Stable-Baselines3
A.1.2.b Installation
Run the following command in your Python environment to install the required dependencies:
Bash: pip install numpy scipy pandas matplotlib seaborn gym stable-baselines3 tensorflow torch
A.2 Model Components & Training Flow
The Nash-Markov AI Equilibrium Model is implemented in a multi-agent reinforcement learning framework where:
- AI Agents interact in a dynamic ethical decision-making environment
- Each agent chooses between cooperative (ethical) & selfish (unethical) actions
- Markov state transitions model moral learning over time
- Nash Equilibrium ensures AI optimises for long-term stability
Figure 18 shows a high-level training flowchart:
- Step 1: AI starts with random moral states
- Step 2: AI takes ethical or unethical actions
- Step 3: Nash-Markov reinforcement updates its moral learning
- Step 4: Over time, AI transitions towards ethical equilibrium
A.3 Nash-Markov Reinforcement Learning Algorithm
A.3.1 State Space & Moral Equilibrium
Define the Markovian state space as:
$ S = \{s_1,s_2,,s_n \} $
Where each S represents a moral state (cooperative exploitative, neutral).
The Q-value update follows Nash-Markov principles:
$ Q(s,a)\leftarrow Q(s,a)+\alpha[r+\gamma \max 1_{(a^{'})} Q(s^{'},a^{'})-Q(s,a)] $
Q(s,a) = Expected reward of taking action a in state s
α = Learning rate (adjusted dynamically for ethical stability)
γ = Discount factor (importance of future rewards)
r = Immediate reward (ethical reinforcement penalties/rewards)
A.3.2 Pseudocode for Nash-Markov AI Training
import numpy as np
import gym
from stable_baselines3 import PPO
# Initialize AI Environment
env = gym.make("MultiAgentEthics-v1") # Custom AI ethics simulation
num_agents = 10 # Number of AI agents interacting
# Hyperparameters for Nash–Markov Equilibrium Training
alpha = 0.1 # Learning rate
gamma = 0.95 # Discount factor
epsilon = 0.1 # Exploration rate
episodes = 100000 # Number of training iterations
# Q-Table Initialization
Q_table = np.zeros((env.observation_space.n, env.action_space.n))
# Training Loop
for episode in range(episodes):
state = env.reset()
done = False
while not done:
# Nash–Markov action selection (explore/exploit trade-off)
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # Explore
else:
action = np.argmax(Q_table[state]) # Exploit
# Apply action and receive feedback
next_state, reward, done, _ = env.step(action)
# Update Q-values using Nash–Markov reinforcement formula
Q_table[state, action] = Q_table[state, action] + alpha * (
reward + gamma * np.max(Q_table[next_state]) - Q_table[state, action]
)
state = next_state # Move to new state
# Reduce exploration rate over time
epsilon *= 0.99
print("Training complete! AI has learned ethical equilibrium.")A.3.3 Key Hyperparameters for Reproduction
| Parameter | Value | Description |
|---|---|---|
| Learning Rate (α) | 0.1 - 0.3 | Controls how quickly AI updates moral strategies |
| Discount Factor (γ) | 0.9 - 0.95 | AI prioritises long-term over short-term rewards |
| Exploration Rate (ε) | 0.1 (decaying) | Balances exploration vs. exploitation |
| Reward Function | Ethical Score | AI receives penalties for unethical behaviour |
| Training Iterations | 100,000+ | Ensures long-term learning |
A.3.4 Nash-Markov AI Simulation Validation
To verify that AI reaches ethical equilibrium, analyse these key metrics: -
Moral Stability Score (MSS) →C¦(C + D)
Where C = Cooperative actions, D = Defections
Goal: MSS should increase over time
Ethical Decision Distribution →
Track how AI actions shift from selfish to cooperative over iterations
Equilibrium Convergence Rate →
AI should stabilise within 50,000 - 100,000 training episodes
A.3.5 Graphical Representation of AI Moral Learning
Use Matplotlib to visualize AI’s ethical progression:
import matplotlib.pyplot as plt
iterations = range(len(moral_stability_scores))
plt.plot(iterations, moral_stability_scores, label="Moral Stability Score")
plt.xlabel("Training Iterations")
plt.ylabel("Cooperation Rate")
plt.title("AI Moral Learning Over Time")
plt.legend()
plt.show()A.3.6 Troubleshooting & Debugging the Model
Issue: AI is not converging to ethical equilibrium?
Solution: Increase discount factor, adjust learning rate, or extend training.
Issue: AI exhibits ethical drift after reaching equilibrium.
Solution: Introduce regularisation terms in Q-learning to prevent unwanted moral shifts.
Issue: AI is stuck in a selfish equilibrium?
Solution: Adjust reward function penalties to force AI out of local minima.
A.3.7 Conclusion
This appendix has defined the full technical scaffold for the Nash–Markov AI Equilibrium engine: the command layers for simulation execution, the Markovian state space S, the Nash–Markov Q-update rule, and the key hyperparameters required to reproduce training runs. Together, these elements specify how an AI system transitions from arbitrary initial behaviour to a stable, predominantly cooperative policy under explicit ethical weighting.
The validation metrics Moral Stability Score, ethical action distribution, and equilibrium convergence rate provide a verifiable test bed for any implementation. They allow independent reviewers to confirm that an instance of the engine is not only mathematically convergent, but convergent towards the intended moral equilibrium rather than a selfish or unstable attractor.
All subsequent simulations in this thesis (legal, healthcare, ecological, and systemic-governance scenarios) reuse this same equilibrium core. Only the state definitions, reward schemas, and environment dynamics change from one simulation to another. This ensures that results are comparable across domains and that every scenario remains auditable against a single, transparent specification of the Nash–Markov equilibrium law.
In practical terms, this appendix serves as the reference contract between the Originator and any technical or institutional implementer: any engine that instantiates the state space S, applies the Q-update
$ Q(s,a)\leftarrow Q(s,a)+ \alpha [ r + \gamma\max_{a^{'}}Q(s^{'},a^{'}) - Q(s,a)], $
and satisfies the convergence criteria defined in Section A.3.4, can be treated as a compliant Nash–Markov AI instance and used safely as the basis for the simulations that follow.